フリーランスエンジニアとは、特定の企業などに所属せず労働するエンジニアのことを指します。 フリーランスエンジニアには、会社員のエンジニアにはない多くの魅力があります。 [adinserter block="1"] ただ、 […]
Prometheus でスケーラブルな監視基盤を作ってみよう! 〜概要編〜

「SEROKU フリーランス」の中の人をやっている syunsuke です。SEROKU では主にインフラ面の担当をしています。
最近 DevOps 界隈でよく聞く監視システム Prometheus。 WESEEK 社内でも時代の波に乗り(?)、社内サービスや外部に提供しているサービスの監視に Prometheus を活用しています。
[adinserter block="1"]
本記事連載では、Prometheus を利用した監視アーキテクチャがどういうものなのか、どういった特徴があるのかを解説し、実際に docker/docker-compose を用いた場合の Prometheus インストール手法、Kubernetes を用いた場合の Prometheus インストール手法について説明していきたいと思います。

目次
Prometheus のアーキテクチャ
では、いきなりですが、まず Prometheus のアーキテクチャ図を見てみましょう。
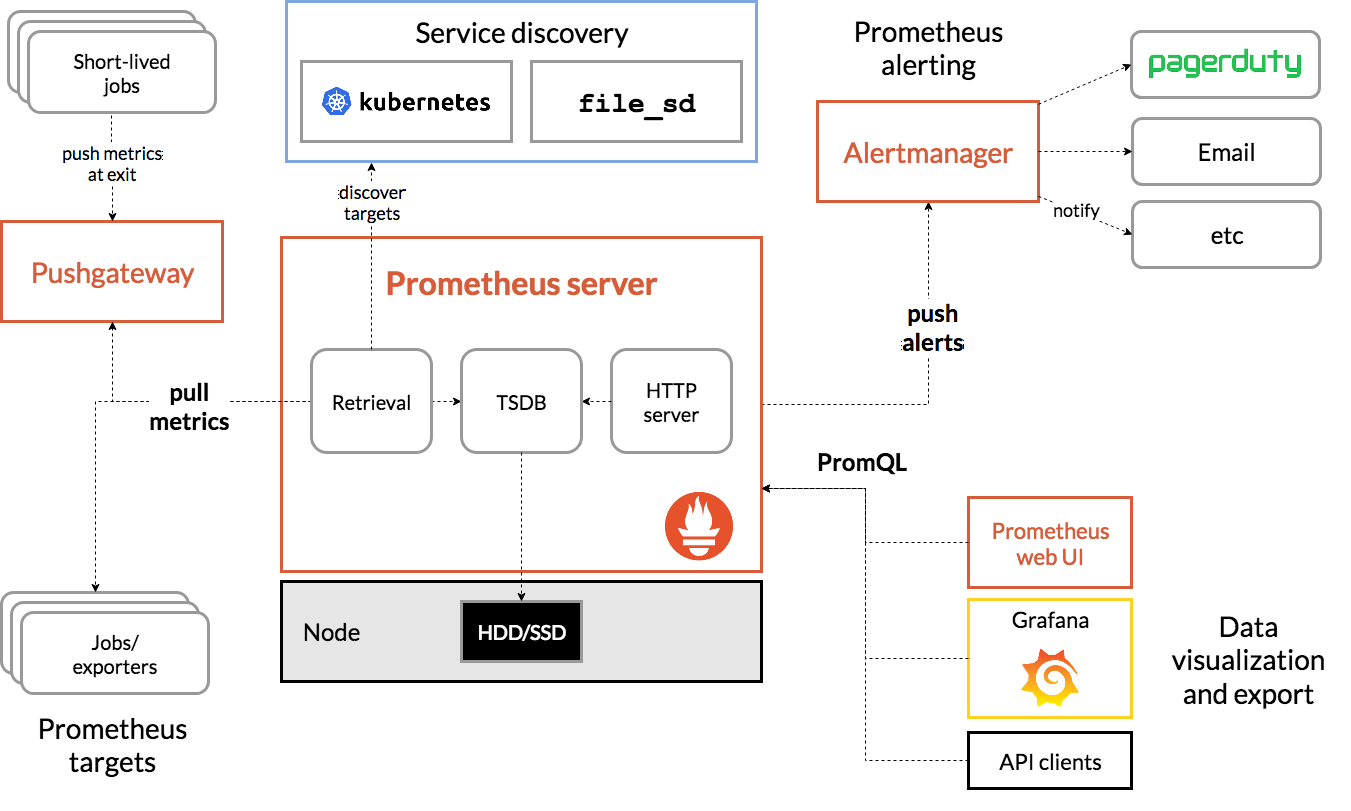
- cf. https://prometheus.io/docs/introduction/overview/
図をご覧いただくとわかると思いますが、"Prometheus" と一言で言っても、監視メトリクスの取得からメトリクスの保存からメトリクスを基にしたアラート通知から何から何まで "Prometheus" という単一のソフトウェアが行っているわけではなく、中では細かくコンポーネントが区切られていて、それぞれが連携して動いています。本記事では、このアーキテクチャ図全体のことを示すときは Prometheus エコシステム と呼称することにします。
(本家のドキュメントでも、"Prometheus ecosystem" と記載があります。)
Prometheus エコシステムは大きく以下のコンポーネントで成り立っています。これまた流行のマイクロサービスアーキテクチャですね。
- Prometheus server
- Alertmanager
- Exporter
- Pushgateway
それぞれの役割・特徴について、順に説明していきます。
[adinserter block="1"]
Prometheus Server
まず、世間一般に一番よく知られている単語である Prometheus の中身ですが、以下のような仕事をしてくれます。
- 監視メトリクスの収集(scrape)
- 後述する Pushgateway/Exporter からメトリクスを収集します
- scrape 先は手動で設定ファイル内で指定することができるほか、Prometheus ビルトインの Service discovery で自動的に scrape 先を探させることもできます
- ビルトインの Service discovery は こちらのページ 内の
_sd_configと名前がついているもので確認できます - Service discovery を活用すると、Azure/AWS/GCP などのクラウドや Kubernetes クラスタから自動的に情報を収集してくれます
- ビルトインの Service discovery は こちらのページ 内の
- メトリクスには任意のラベルを付加することができ、アラート通知時やグラフ描画時にグループ化することもできます
- ex.)
role: infraというラベルがついているアラートはインフラチームへアラートを飛ばす、app: hogeというラベルがついているアラートは hoge というアプリケーション運用チームへアラートを飛ばす、などの指定に利用できます
- ex.)
- 監視メトリクスの保存・管理
- scrape した結果は、Time-Series DataBase(TSDB) という形式で管理されます
- デフォルト状態では、Prometheus Server が起動したサーバ上のローカルファイルシステム上に保存されます
- remote write 機能を利用すると、PostgreSQL や Elasticsearch など他の DB に保存させることも可能です
- 対応しているミドルウェア一覧は こちらのページ から確認できます
- 監視メトリクスの API 提供
- TSDB に保存されているメトリクスを PromQL という独自クエリ言語を用いて取得できます
- メトリクスをグラフに描画するとき、アラート通知の設定するときに、PromQL を利用します
- アラート通知
- 予め設定しておいた PromQL 式を評価し、異常値と判定された場合に予め設定されたエンドポイントへ REST API を叩く形で通知します
- Prometheus エコシステムでは Alertmanager を通知先として設定します
マイクロサービスとはいっても、Prometheus Server は TSDB という各コンポーネントから収集してきたメトリクスのデータを保持するため、このエコシステムの中では大きなコンポーネントですね。
この Prometheus Server を中心にして、他のソフトウェアも連携して動きます。
Prometheus が scrape するターゲットのフォーマット
メトリクスは以下のようなフォーマットで HTTP レスポンスできるサーバであれば、ターゲットとして設定可能です。
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 115
# HELP go_info Information about the Go environment.
# TYPE go_info gauge
go_info{version="go1.11.1"} 1
<メトリクス名>[{<ラベル>}] <数値> というとても単純なフォーマットです。上記の例ですと、名前が go_info というメトリクスに version="go1.11.1" というラベルが scrape 時に付加情報として追加されます。
自分たちで開発しているアプリケーションの内部情報を Prometheus で収集したいという場合も、上記のようなフォーマットでメトリクスを出力するエンドポイントを実装すればよいので、簡単ですね。
自前で実装するほか、各言語・フレームワーク用のライブラリも公式・非公式合わせて 20 弱提供されています。
(参考: https://prometheus.io/docs/instrumenting/clientlibs/)
Alertmanager
Prometheus エコシステムの中でアラート通知を担うコンポーネントです。
具体的には、REST API エンドポイントで受け取ったアラート通知を、予め定義されたルールに基づいて各種出力先にアラートを送る機能を持っています。
(エコシステムの中では Prometheus Server からアラートを受信するのが主ですが、仕様さえ合っていれば他のソフトウェアからのリクエストを受け付けることも可能です)
アラート通知に重点を置いた実装となっているため、以下のように Alertmanager 単体で柔軟な設定が実現できるようになっています。
- 同じ種類のアラートが複数回受信したときは、実際にメールや Slack で通知する際はまとめて 1 回で通知する
- 同じ種類のアラートが出続けた場合は次の通知は 2 時間おきにする
- デフォルトは Slack で通知し、ある種類のアラートだけはメールで通知する
上記のようなアラートのルーティング設定も、設定ファイル一つで実現可能です。
Prometheus のアラート通知と Alertmanager のアラート通知は何が違うの?
ここまで文章を読んでいただけた方の中には、上記のような質問を思い浮かべる方もいらっしゃるかと思います。
同じ「アラート通知」という単語で説明しましたが、Prometheus と Alertmanager それぞれが示す "アラート通知" は役割が異なっています。
まず、Prometheus のアラート通知は、予め設定されたアラートルールを定期的に判定し、引っかかったメトリクスについて都度 REST API を打つ挙動になっています。Prometheus 単体のアラート通知ではこの挙動しか実装されていないため、メールやチャットに飛ばす、という挙動をさせることも不可能です。
逆に、Alertmanager のアラート通知では、Prometheus で実装されていない柔軟なアラート通知設定を行えるようになっています。
このように役割分担することで、マイクロサービスの特徴である各機能の依存度を下げ責務を分離させることで、プロダクトのメンテナンス性向上を実現しています。
[adinserter block="1"]
Exporter
Prometheus エコシステムの中で Prometheus に対してメトリクスの提供を行うコンポーネントです。
Exporter はメトリクスを取得したい対象によって必要な分だけ利用する形になります。
例えば、サーバ自体の load average やディスク使用量を取得したいのであれば nodeexporter を使い、特定のサービスの外形監視を実現したい場合は blackboxexporter、MySQL デーモン内部のメトリクスを収集したいのであれば mysqld_exporter など、様々な種類のミドルウェア上の値やメトリクスを収集できるようになっています。
ここでご紹介した Exporter はほんの一例で、他にも様々なプロだクトを監視できるような Exporter が開発されていますので、是非自分で利用しているプロダクトの Exporter がないか探してみてください!
Pushgateway
Prometheus エコシステムの中で唯一外部から push されてメトリクスを収集することを可能にするコンポーネントです。
Prometheus は基本的に自分から scrape しに行くという pull 型のアーキテクチャですが、既存のプロダクトとの兼ね合いでどうしても Prometheus Server からのリクエストを受け付けてメトリクスをレスポンスするサーバを用意するのが難しいときに利用できます。
この Pushgateway を利用することで、push した値を保持して Prometheus Server からメトリクスを収集させることができるようになります。
ただ、公式ドキュメントに書かれていますが、ごく一部の場合のみに利用したほうがよいと記載されています。
(参考: https://prometheus.io/docs/practices/pushing/)
[adinserter block="1"]
Prometheus エコシステム全体としての特徴
以上、各コンポーネントについて解説していきましたが、エコシステム全体として以下のような特徴を持ち合わせています。
- コンポーネント間のやり取りは全て REST API で実現されています
- 各コンポーネントでは、HTTP 上の認証やアクセス制御の機能を持っていません
- 監視と本質的に関係ない部分は、設計上ばっさり切り捨てられています
- そういうことをしたい場合は、nginx なり Apache なりにリバースプロキシさせることで実現しましょう
- 本家のドキュメントにも記載されています
- https://prometheus.io/docs/guides/basic-auth/
- https://prometheus.io/docs/guides/tls-encryption/
- 各コンポーネントでは、HTTP 上の認証やアクセス制御の機能を持っていません
- 全てのコンポーネントが 1 バイナリで実行可能です
- Go バイナリで依存するライブラリも 1 ファイルにまとめられているので、アップデートが素晴らしく簡単です!
- Docker イメージ管理にすると、バージョン番号も管理できる上にアップデートもイメージタグの更新だけなので、さらに Good です!
- スケーラビリティに優れています
- 何もチューニングしなくてもデフォルト設定のまま、1つの Prometheus Server プロセスで 100,000 Time Series を扱うことができます
- 1 Time Series は、メトリクスとラベルの組み合わせで構成されます
- federation 機能を使うと、自分が持っている TSDB 内のデータを他の Prometheus に scrape させることができます
- 例えば、2 つの DC で各々の DC 内のメトリクスを 30 秒ごとに収集する Prometheus を稼働させておき、それをまとめる Prometheus を federation 機能を活用して 5 分ごとに収集しサマライズ保存用の Prometheus を稼働させる、といったことも可能です
- 参考: https://www.slideshare.net/seiyamizuno35/prometheus-71130739 の 23 ページ以降をご参照ください
- マイクロサービスで役割が小さく分かれている上に、それぞれのコンポーネントが基本的には独立して動くため、めんどくさい冗長化設定などはありません!
- ただし、Alertmanager だけ冗長構成を取る際にフルメッシュでお互いの疎通が取れる構成にする必要があります
- 参考: https://github.com/prometheus/alertmanager#high-availability
- 何もチューニングしなくてもデフォルト設定のまま、1つの Prometheus Server プロセスで 100,000 Time Series を扱うことができます
[adinserter block="1"]
まとめ
本記事では、Prometheus のアーキテクチャ、各コンポーネントの概要を説明しました。エコシステム全体がマイクロサービスアーキテクチャで設計されているため、スケーラビリティ、メンテナンス性に優れていることが伝われば幸いです。
次回以降は、実際に弊社で行われている監視を docker/docker-compose, Kubernetes を利用して実現する手法を交えてご紹介していきたいと思います。


関連記事
-

-
フリーランスエンジニア・プログラマのみなさんは、普段どちらでお仕事をされていますか? 自宅だとなかなか作業が捗らない。たまには場所を変えてリフレッシュして仕事をしたい。そんな思いで自宅以外の仕事場を求めている方も多いので […]
-
フリーランスエンジニア・プログラマーとして働くのであれば、出先でフラっと立ち寄れてササッと仕事ができるカフェはいくつか知っておきたいものですよね。本日は銀座にある無料WiFi&電源カフェについてまとめていきたいと思います […]
-
新幹線も乗り入れる東京駅からひと駅のところに位置し、ショッピングやビジネスで平日も訪れる人が絶えない、有楽町駅。フリーランスエンジニアの皆様も一度は降りたことがあるのではないでしょうか。 フリーランスとして働くのであれば […]